SIMLIN: an improved bioinformatics approach based on multi-stage ensemble learning model for S-sulphenylation prediction
S-sulphenylation, a kind of post translational modification process, is a reversible covalent binding of hydroxyl group towards the thiol group of the cysteine residue so that S-hydroxyl (-SOH) can be formed. Because current biological evidence shows that this procedure plays critical roles in many aspects of proteins’ regulation and the experimental approach on this topic is not only expensive but also time-consuming, a comprehensive bioinformatics approach is necessary so that these kind of sulfenic modification reaction can be further studied. One of the biggest vulnerability of current computational approach on S-sulphenylation prediction is that it is highly dependent on the pre-classification of the sequence motifs, and a combination of 10 independent predictive models have been applied towards the entire sequence so that there is one predictive model for each major subcategory of those featured sequence motif, even though the performance of those individual predicative models varies a lot. This work offers a more generalizable approach on this issue by creating a multi-stage neural network based ensemble learning model with 9 different major cluster of features. By using the independent testing dataset of project “SOHSite” for further performance evaluation, this algorithm has successfully scored 0.88 of accuracy rate and 0.82 of AUC value respectively. Most importantly, comparing towards other major algorithms, this algorithm doesn’t require any pre-classification of sequence motifs before feeding them into the predictive model and performance indicators are unified so that the bias between each individual predictive result can be minimized.
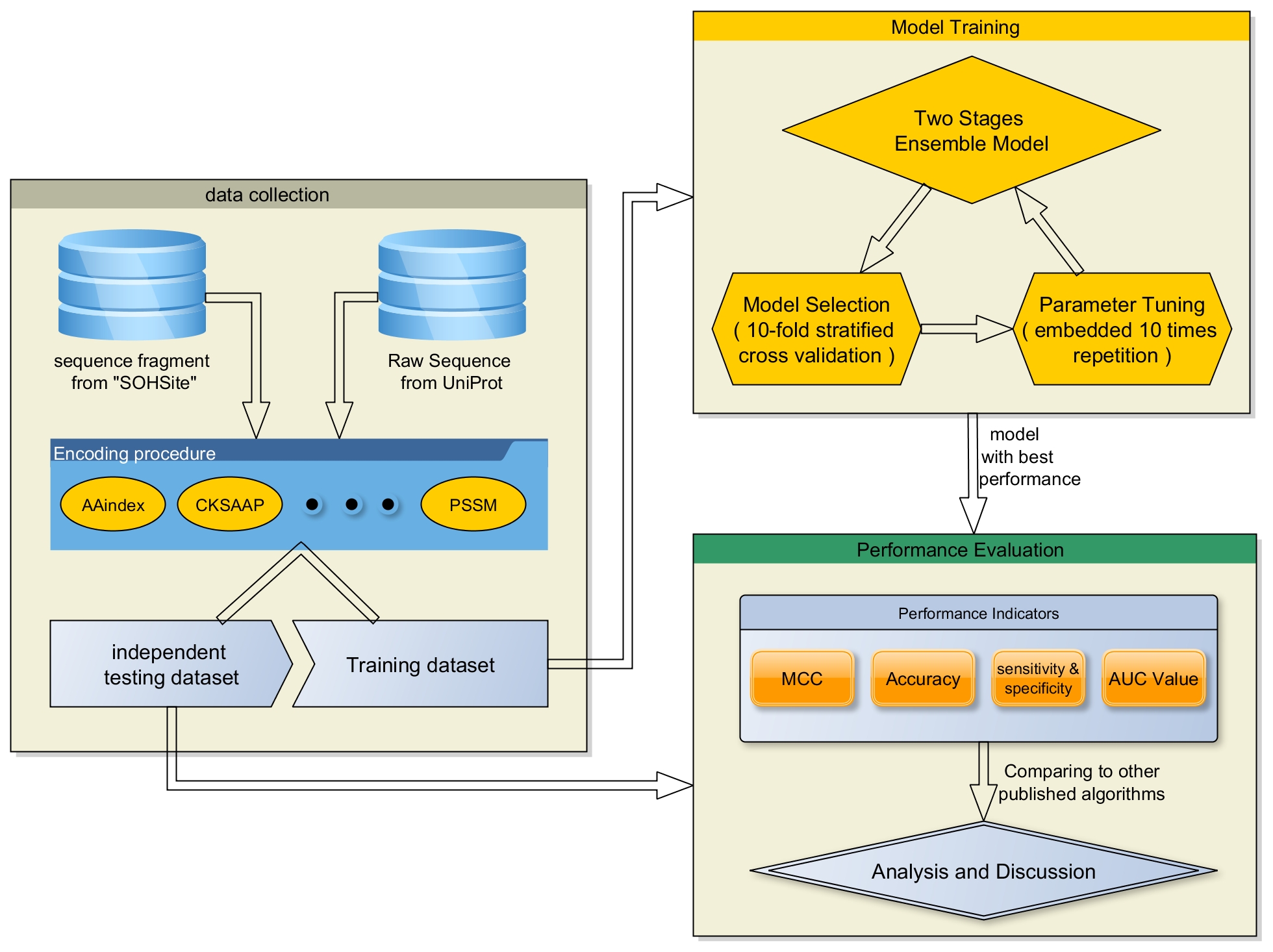
Figure 1. The overall structure illustration for the ensemble learning model construction and performance evaluation
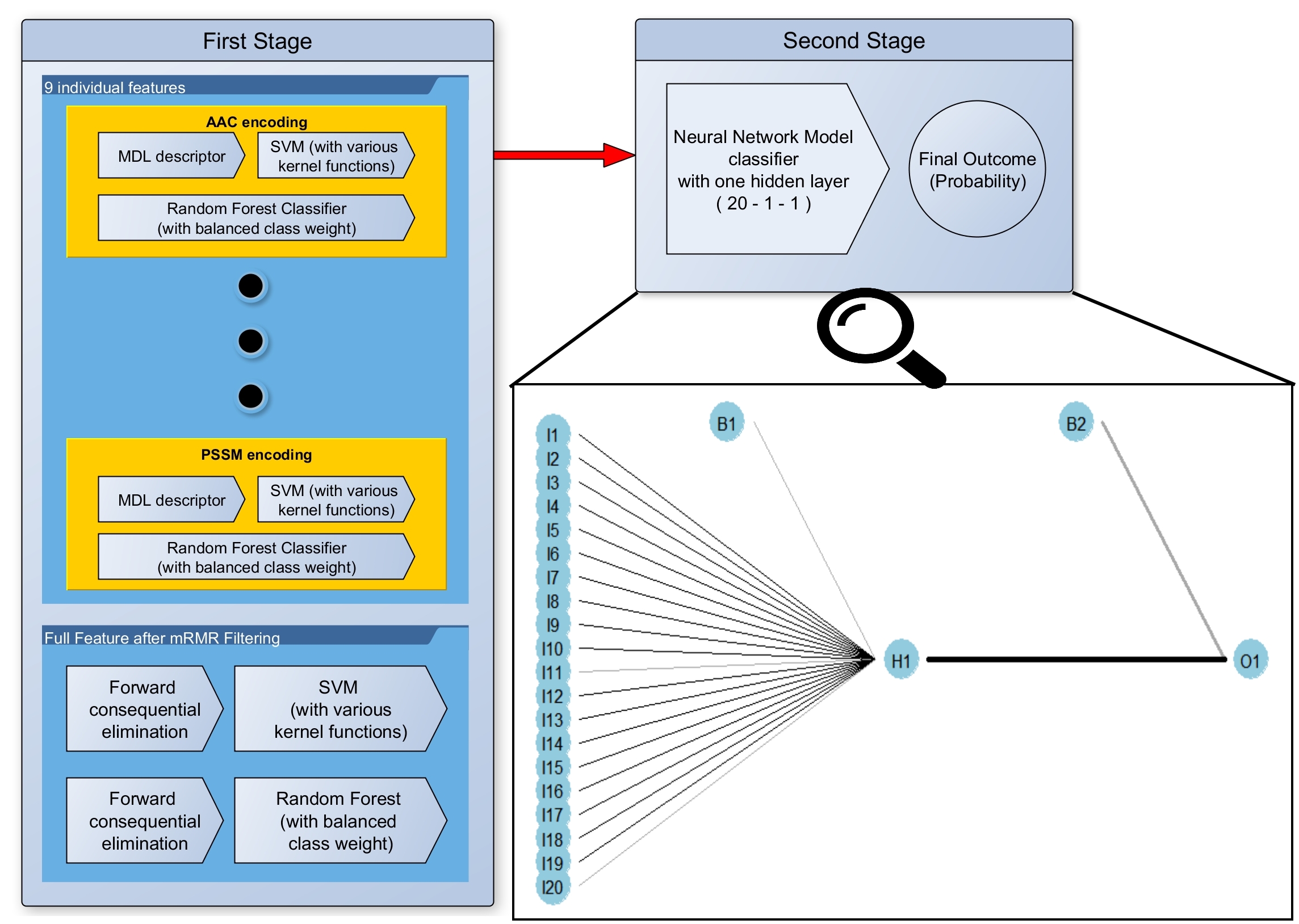
figure 2. The illustration of the final multi-stage ensemble learning model
Productive Service
Instructions: Step 1. Please fill in your contact Email address. Step 2. Please upload your protein sequence (fasta/text format). For example: >sp|Q9HAW0|BRF2_HUMAN Transcription factor IIIB 50 kDa subunit OS=Homo sapiens OX=9606 GN=BRF2 PE=1 SV=1 MPGRGRCPDCGSTELVEDSHYSQSQLVCSDCGCVVTEGVLTTTFSDEGNLREVTYSRSTG ENEQVSRSQQRGLRRVRDLCRVLQLPPTFEDTAVAYYQQAYRHSGIRAARLQKKEVLVGC CVLITCRQHNWPLTMGAICTLLYADLDVFSSTYMQIVKLLGLDVPSLCLAELVKTYCSSF KLFQASPSVPAKYVEDKEKMLSRTMQLVELANETWLVTGRHPLPVITAATFLAWQSLQPA DRLSCSLARFCKLANVDLPYPASSRLQELLAVLLRMAEQLAWLRVLRLDKRSVVKHIGDL LQHRQSLVRSAFRDGTAEVETREKEPPGWGQGQGEGEVGNNSLGLPQGKRPASPALLLPP CMLKSPKRICPVPPVSTVTGDENISDSEIEQYLRTPQEVRDFQRAQAARQAATSVPNPP >sp|P35236|PTN7_HUMAN Tyrosine-protein phosphatase non-receptor type 7 OS=Homo sapiens OX=9606 GN=PTPN7 PE=1 SV=3 MVQAHGGRSRAQPLTLSLGAAMTQPPPEKTPAKKHVRLQERRGSNVALMLDVRSLGAVEP ICSVNTPREVTLHFLRTAGHPLTRWALQRQPPSPKQLEEEFLKIPSNFVSPEDLDIPGHA SKDRYKTILPNPQSRVCLGRAQSQEDGDYINANYIRGYDGKEKVYIATQGPMPNTVSDFW EMVWQEEVSLIVMLTQLREGKEKCVHYWPTEEETYGPFQIRIQDMKECPEYTVRQLTIQY QEERRSVKHILFSAWPDHQTPESAGPLLRLVAEVEESPETAAHPGPIVVHCSAGIGRTGC FIATRIGCQQLKARGEVDILGIVCQLRLDRGGMIQTAEQYQFLHHTLALYAGQLPEEPSP >sp|P25874|UCP1_HUMAN Mitochondrial brown fat uncoupling protein 1 OS=Homo sapiens OX=9606 GN=UCP1 PE=1 SV=3 MGGLTASDVHPTLGVQLFSAGIAACLADVITFPLDTAKVRLQVQGECPTSSVIRYKGVLG TITAVVKTEGRMKLYSGLPAGLQRQISSASLRIGLYDTVQEFLTAGKETAPSLGSKILAG LTTGGVAVFIGQPTEVVKVRLQAQSHLHGIKPRYTGTYNAYRIIATTEGLTGLWKGTTPN LMRSVIINCTELVTYDLMKEAFVKNNILADDVPCHLVSALIAGFCATAMSSPVDVVKTRF INSPPGQYKSVPNCAMKVFTNEGPTAFFKGLVPSFLRLGSWNVIMFVCFEQLKRELSKSR QTMDCAT Step 3. Please click the submit button at the bottom Step 4. At the right side, there will be a receipt for your submission, which includes your contact Email, your submission ID, submission date and the queuing status of the task etc. Later, both your contact Email and submission ID are required for retrieving the analysis result